In this tutorial, we demonstrate how to call peaks on a single-cell ATAC-seq dataset using MACS3.
To use the peak calling functionality in Signac you will first need to install MACS3. This can be done using pip or conda, or by building the package from source.
MACS3 uses a dedicated parser for single-cell ATAC-seq fragment files, which contains the barcode information and the counts of the fragments aligned to the same location with the same barcode.
In this demonstration we use scATAC-seq data for human PBMCs. See our vignette for the code used to generate this object, and links to the raw data. First, load the required packages and the pre-computed Seurat object:
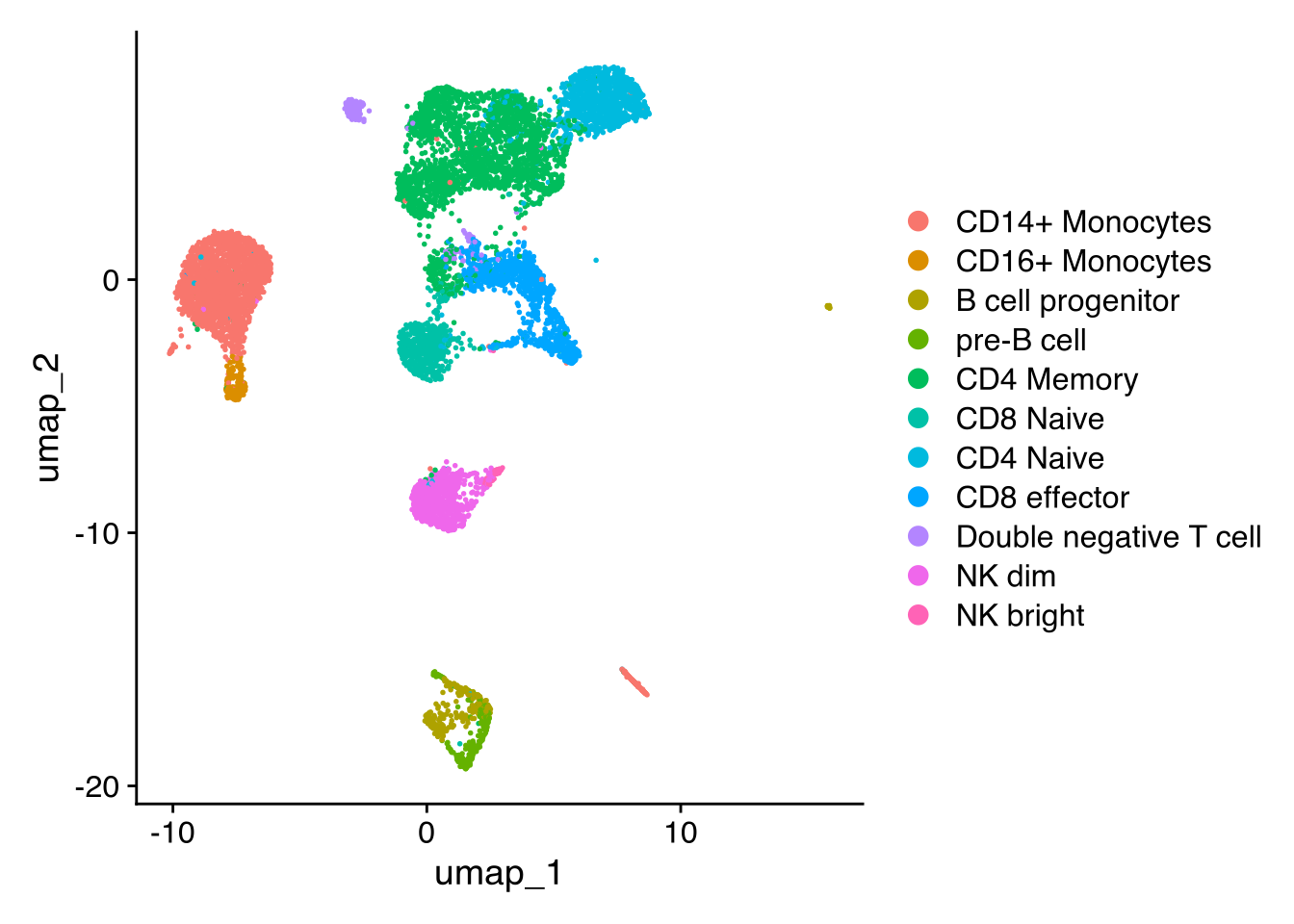
Peak calling with callpeak mode
Peak calling can be performed using the CallPeaks()
function on a Seurat object, ChromatinAssay5
object, Fragment2 object, or by giving the path to a
fragment file on disk.
## GRanges object with 6 ranges and 6 metadata columns:
## seqnames ranges strand | name score
## <Rle> <IRanges> <Rle> | <character> <integer>
## [1] GL000194.1 56039-56324 * | SeuratProject_peak_1 1290
## [2] GL000194.1 101211-101818 * | SeuratProject_peak_2 3425
## [3] GL000194.1 114384-115052 * | SeuratProject_peak_3 8293
## [4] GL000195.1 24088-24460 * | SeuratProject_peak_4 269
## [5] GL000195.1 24972-25447 * | SeuratProject_peak_5 101
## [6] GL000195.1 30539-30907 * | SeuratProject_peak_6 43592
## fold_change neg_log10pvalue_summit neg_log10qvalue_summit
## <numeric> <numeric> <numeric>
## [1] 8.36676 131.1970 129.027
## [2] 15.41060 344.9850 342.510
## [3] 28.31830 832.1450 829.313
## [4] 3.71856 28.7884 26.961
## [5] 2.53863 11.8498 10.180
## [6] 21.13710 4363.3400 4359.280
## relative_summit_position
## <integer>
## [1] 55
## [2] 142
## [3] 628
## [4] 67
## [5] 126
## [6] 303
## -------
## seqinfo: 35 sequences from an unspecified genome; no seqlengthsParallelization across cell groups with future
We have observed that the runtime for MACS3 may be longer than
previous versions of MACS that reads in the input as a standard BED
file. When calling peaks across multiple groups of cells, we recommend
enabling parallelization in R using the future package (see
future::plan() for details on how to configure
parallelization). This will enable peaks to be called in parallel for
each group of cells.
library(future)
# set up workers
plan(multicore, workers = 6)
nbrOfWorkers()## [1] 6To call peaks on each annotated cell type, we can use the
group.by argument:
peaks <- CallPeaks(pbmc, group.by = "predicted.id")The results are returned as a GRanges object, with an
additional metadata column listing the cell types that each peak was
identified in:
| seqnames | start | end | width | strand | peak_called_in |
|---|---|---|---|---|---|
| chr1 | 17334 | 17523 | 190 | * | NK bright |
| chr1 | 180771 | 180948 | 178 | * | CD4 Memory |
| chr1 | 191319 | 191882 | 564 | * | CD8 Naive,CD8 effector,CD14+ Monocytes,CD4 Naive |
| chr1 | 267960 | 268402 | 443 | * | pre-B cell |
| chr1 | 271259 | 271459 | 201 | * | CD14+ Monocytes |
| chr1 | 280581 | 280751 | 171 | * | CD14+ Monocytes,CD16+ Monocytes |
To call peaks for specific group(s) of cells, use the
idents argument:
peaks <- CallPeaks(pbmc, group.by = "predicted.id", idents = "CD16+ Monocytes")By default, CallPeaks() will combine all peak calls into
one GRanges object. Set combine.peaks = FALSE
to return a list with a GRanges object for each group:
peaks_separate <- CallPeaks(
object = pbmc,
group.by = "predicted.id",
idents = c("CD4 Naive", "CD4 Memory"),
combine.peaks = FALSE
)| seqnames | start | end | width | strand | name | score | fold_change | neg_log10pvalue_summit | neg_log10qvalue_summit | relative_summit_position | ident |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GL000194.1 | 56039 | 56285 | 247 | * | CD4_Memory1_peak_1 | 353 | 8.32754 | 37.54070 | 35.31380 | 36 | CD4 Memory |
| GL000194.1 | 101301 | 101540 | 240 | * | CD4_Memory1_peak_2 | 267 | 7.09889 | 28.94310 | 26.77900 | 169 | CD4 Memory |
| GL000194.1 | 114650 | 115052 | 403 | * | CD4_Memory1_peak_3 | 2605 | 31.39890 | 263.37900 | 260.50300 | 363 | CD4 Memory |
| GL000195.1 | 23147 | 23364 | 218 | * | CD4_Memory1_peak_4 | 32 | 2.73034 | 4.95946 | 3.20431 | 211 | CD4 Memory |
| GL000195.1 | 24997 | 25313 | 317 | * | CD4_Memory1_peak_5 | 111 | 4.50506 | 13.16170 | 11.16900 | 162 | CD4 Memory |
| GL000195.1 | 30545 | 30907 | 363 | * | CD4_Memory1_peak_6 | 12271 | 21.46080 | 1231.29000 | 1227.16000 | 298 | CD4 Memory |
| seqnames | start | end | width | strand | name | score | fold_change | neg_log10pvalue_summit | neg_log10qvalue_summit | relative_summit_position | ident |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GL000194.1 | 114851 | 115039 | 189 | * | CD4_Naive1_peak_1 | 614 | 19.27360 | 64.16790 | 61.46570 | 162 | CD4 Naive |
| GL000195.1 | 24324 | 24631 | 308 | * | CD4_Naive1_peak_2 | 59 | 4.73940 | 7.96245 | 5.90732 | 29 | CD4 Naive |
| GL000195.1 | 25046 | 25202 | 157 | * | CD4_Naive1_peak_3 | 35 | 3.79152 | 5.51723 | 3.58620 | 78 | CD4 Naive |
| GL000195.1 | 30550 | 30908 | 359 | * | CD4_Naive1_peak_4 | 5773 | 22.00480 | 581.76600 | 577.30100 | 295 | CD4 Naive |
| GL000195.1 | 32430 | 32901 | 472 | * | CD4_Naive1_peak_5 | 1795 | 10.25540 | 182.72100 | 179.54800 | 44 | CD4 Naive |
| GL000195.1 | 47021 | 47177 | 157 | * | CD4_Naive1_peak_6 | 43 | 4.10748 | 6.30163 | 4.32319 | 143 | CD4 Naive |
To quantify counts in each peak, you can use the
FeatureMatrix() function.
We can visualize the cell-type-specific MACS3 peak calls alongside
the 10x Cellranger peak calls (currently being used in the
pbmc object) with the CoveragePlot()
function:
CoveragePlot(
object = pbmc,
region = "CD8A",
ranges = peaks,
ranges.title = "MACS3"
)## Warning: Removed 1 row containing missing values or values outside the scale range
## (`geom_segment()`).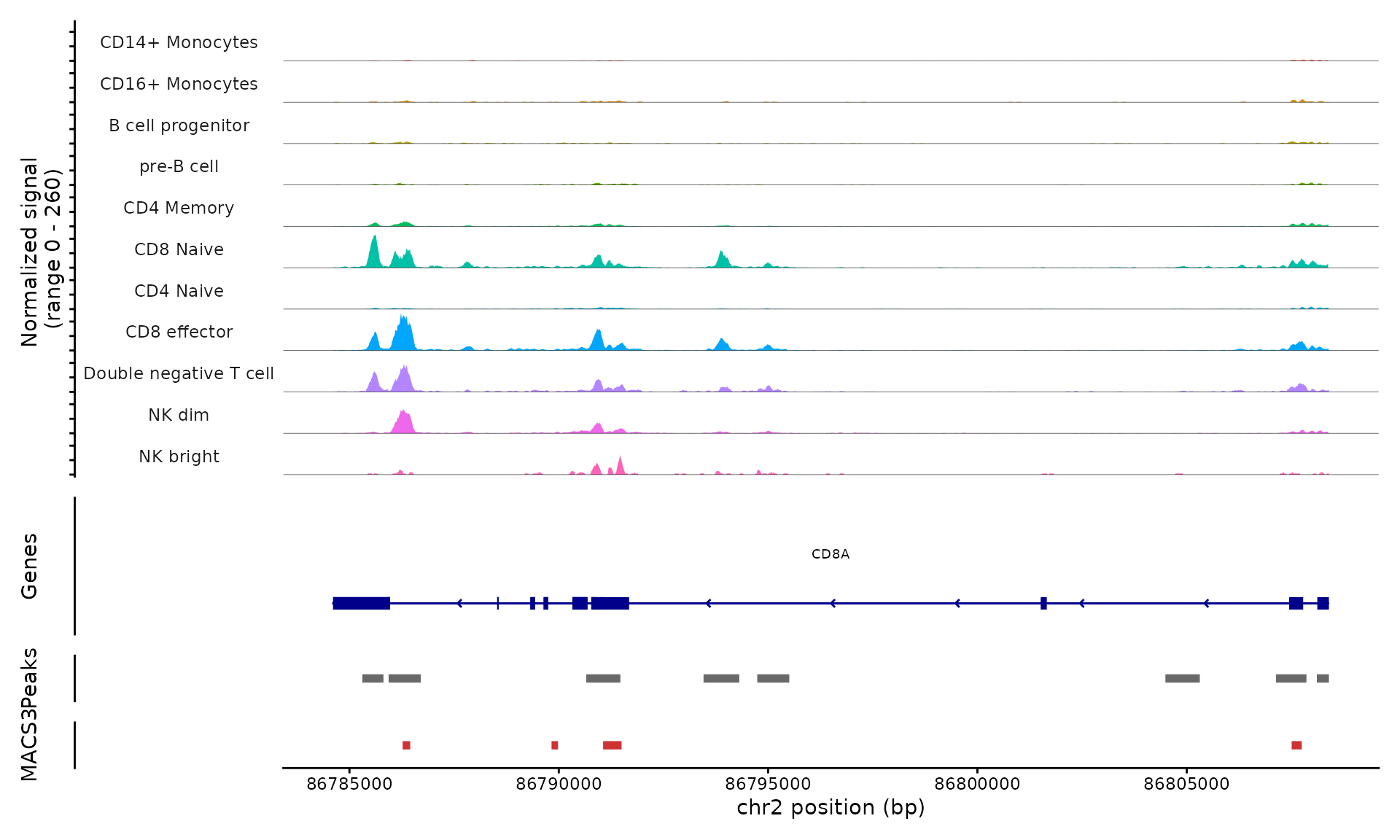
Session Info
## R version 4.5.1 (2025-06-13)
## Platform: aarch64-apple-darwin20
## Running under: macOS Tahoe 26.5.2
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## time zone: Australia/Perth
## tzcode source: internal
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] future_1.75.0 Seurat_5.5.1 SeuratObject_5.4.0 sp_2.2-3
## [5] Signac_1.9999.6
##
## loaded via a namespace (and not attached):
## [1] RColorBrewer_1.1-3 jsonlite_2.0.0
## [3] magrittr_2.0.5 spatstat.utils_3.2-4
## [5] farver_2.1.2 rmarkdown_2.31
## [7] fs_2.1.0 ragg_1.5.2
## [9] vctrs_0.7.3 ROCR_1.0-12
## [11] spatstat.explore_3.8-2 Rsamtools_2.26.0
## [13] RcppRoll_0.3.2 htmltools_0.5.9
## [15] S4Arrays_1.10.1 SparseArray_1.10.10
## [17] sass_0.4.10 sctransform_0.4.3
## [19] parallelly_1.48.0 KernSmooth_2.23-26
## [21] bslib_0.11.0 htmlwidgets_1.6.4
## [23] desc_1.4.3 ica_1.0-3
## [25] plyr_1.8.9 plotly_4.12.1
## [27] zoo_1.8-15 cachem_1.1.0
## [29] igraph_2.3.3 mime_0.13
## [31] lifecycle_1.0.5 pkgconfig_2.0.3
## [33] Matrix_1.7-6 R6_2.6.1
## [35] fastmap_1.2.0 MatrixGenerics_1.22.0
## [37] fitdistrplus_1.2-6 shiny_1.14.0
## [39] digest_0.6.39 patchwork_1.3.2
## [41] S4Vectors_0.48.1 tensor_1.5.1
## [43] RSpectra_0.16-2 irlba_2.3.7
## [45] textshaping_1.0.5 GenomicRanges_1.62.1
## [47] labeling_0.4.3 progressr_1.0.0
## [49] spatstat.sparse_3.2-0 polyclip_1.10-7
## [51] httr_1.4.8 abind_1.4-8
## [53] compiler_4.5.1 withr_3.0.3
## [55] S7_0.2.2 BiocParallel_1.44.0
## [57] fastDummies_1.7.6 MASS_7.3-66
## [59] DelayedArray_0.36.1 tools_4.5.1
## [61] lmtest_0.9-40 otel_0.2.0
## [63] httpuv_1.6.17 future.apply_1.20.2
## [65] goftest_1.2-3 glue_1.8.1
## [67] InteractionSet_1.38.0 nlme_3.1-170
## [69] promises_1.5.0 grid_4.5.1
## [71] Rtsne_0.17 cluster_2.1.8.2
## [73] reshape2_1.4.5 generics_0.1.4
## [75] spatstat.data_3.1-9 gtable_0.3.6
## [77] tidyr_1.3.2 data.table_1.18.4
## [79] stringfish_0.19.0 XVector_0.50.0
## [81] spatstat.geom_3.8-2 BiocGenerics_0.56.0
## [83] RcppAnnoy_0.0.23 ggrepel_0.9.8
## [85] RANN_2.6.2 pillar_1.11.1
## [87] stringr_1.6.0 spam_2.11-4
## [89] RcppHNSW_0.7.0 later_1.4.8
## [91] splines_4.5.1 dplyr_1.2.1
## [93] lattice_0.22-9 deldir_2.0-4
## [95] survival_3.8-9 tidyselect_1.2.1
## [97] Biostrings_2.78.0 miniUI_0.1.2
## [99] pbapply_1.7-4 knitr_1.51
## [101] gridExtra_2.3.1 IRanges_2.44.0
## [103] Seqinfo_1.0.0 SummarizedExperiment_1.40.0
## [105] scattermore_1.2 stats4_4.5.1
## [107] xfun_0.60 Biobase_2.70.0
## [109] matrixStats_1.5.0 stringi_1.8.7
## [111] UCSC.utils_1.6.1 yaml_2.3.12
## [113] evaluate_1.0.5 codetools_0.2-20
## [115] tibble_3.3.1 cli_3.6.6
## [117] RcppParallel_5.1.11-2 uwot_0.2.4
## [119] xtable_1.8-8 reticulate_1.46.0
## [121] systemfonts_1.3.2 jquerylib_0.1.4
## [123] dichromat_2.0-1 Rcpp_1.1.2
## [125] GenomeInfoDb_1.46.2 spatstat.random_3.5-1
## [127] globals_0.19.1 png_0.1-9
## [129] spatstat.univar_3.2-0 parallel_4.5.1
## [131] pkgdown_2.2.1 ggplot2_4.0.3
## [133] dotCall64_1.2 sparseMatrixStats_1.22.0
## [135] bitops_1.0-9 listenv_1.0.0
## [137] viridisLite_0.4.3 scales_1.4.0
## [139] ggridges_0.5.7 purrr_1.2.2
## [141] crayon_1.5.3 rlang_1.3.0
## [143] qs2_0.2.2 cowplot_1.2.0
## [145] fastmatch_1.1-8