Joint single-cell mitochondrial DNA genotyping and DNA accessibility analysis
Caleb Lareau and Tim Stuart
Compiled: October 13, 2023
Source:vignettes/mito.Rmd
mito.RmdHere, we take a look at two different datasets containing both DNA accessibility measurements and mitochondrial mutation data in the same cells. One was sampled from a patient with a colorectal cancer (CRC) tumor, and the other is from a polyclonal TF1 cell line. This data was produced by Lareau and Ludwig et al. (2020), and you can read the original paper here: https://doi.org/10.1038/s41587-020-0645-6.
Processed data files, including mitochondrial variant data for the CRC and TF1 dataset is available on Zenodo here: https://zenodo.org/record/3977808
Raw sequencing data and DNA accessibility processed files for the these datasets are available on NCBI GEO here: https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE142745
View data download code
The required files can be downloaded by running the following lines in a shell:
# ATAC data
wget https://zenodo.org/record/3977808/files/CRC_v12-mtMask_mgatk.filtered_peak_bc_matrix.h5
wget https://zenodo.org/record/3977808/files/CRC_v12-mtMask_mgatk.singlecell.csv
wget https://zenodo.org/record/3977808/files/CRC_v12-mtMask_mgatk.fragments.tsv.gz
wget https://zenodo.org/record/3977808/files/CRC_v12-mtMask_mgatk.fragments.tsv.gz.tbi
# mitochondrial allele data
wget https://zenodo.org/record/3977808/files/CRC_v12-mtMask_mgatk.A.txt.gz
wget https://zenodo.org/record/3977808/files/CRC_v12-mtMask_mgatk.C.txt.gz
wget https://zenodo.org/record/3977808/files/CRC_v12-mtMask_mgatk.G.txt.gz
wget https://zenodo.org/record/3977808/files/CRC_v12-mtMask_mgatk.T.txt.gz
wget https://zenodo.org/record/3977808/files/CRC_v12-mtMask_mgatk.depthTable.txt
wget https://zenodo.org/record/3977808/files/CRC_v12-mtMask_mgatk.chrM_refAllele.txtColorectal cancer dataset
To demonstrate combined analyses of mitochondrial DNA variants and accessible chromatin, we’ll walk through a vignette analyzing cells from a primary colorectal adenocarcinoma. The sample contains a mixture of malignant epithelial cells and tumor infiltrating immune cells.
Loading the DNA accessibility data
First we load the scATAC-seq data and create a Seurat object following the standard workflow for scATAC-seq data.
# load counts and metadata from cellranger-atac
counts <- Read10X_h5(filename = "../vignette_data/mito/CRC_v12-mtMask_mgatk.filtered_peak_bc_matrix.h5")
metadata <- read.csv(
file = "../vignette_data/mito/CRC_v12-mtMask_mgatk.singlecell.csv",
header = TRUE,
row.names = 1
)
# load gene annotations from Ensembl
annotations <- GetGRangesFromEnsDb(ensdb = EnsDb.Hsapiens.v75)
# change to UCSC style since the data was mapped to hg19
seqlevels(annotations) <- paste0('chr', seqlevels(annotations))
genome(annotations) <- "hg19"
# create object
crc_assay <- CreateChromatinAssay(
counts = counts,
sep = c(":", "-"),
annotation = annotations,
min.cells = 10,
genome = "hg19",
fragments = '../vignette_data/mito/CRC_v12-mtMask_mgatk.fragments.tsv.gz'
)
crc <- CreateSeuratObject(
counts = crc_assay,
assay = 'peaks',
meta.data = metadata
)
crc[["peaks"]]## ChromatinAssay data with 81787 features for 3535 cells
## Variable features: 0
## Genome: hg19
## Annotation present: TRUE
## Motifs present: FALSE
## Fragment files: 1Quality control
We can compute the standard quality control metrics for scATAC-seq and filter out low-quality cells based on these metrics.
# Augment QC metrics that were computed by cellranger-atac
crc$pct_reads_in_peaks <- crc$peak_region_fragments / crc$passed_filters * 100
crc$pct_reads_in_DNase <- crc$DNase_sensitive_region_fragments / crc$passed_filters * 100
crc$blacklist_ratio <- crc$blacklist_region_fragments / crc$peak_region_fragments
# compute TSS enrichment score and nucleosome banding pattern
crc <- TSSEnrichment(crc)
crc <- NucleosomeSignal(crc)
# visualize QC metrics for each cell
VlnPlot(crc, c("TSS.enrichment", "nCount_peaks", "nucleosome_signal", "pct_reads_in_peaks", "pct_reads_in_DNase", "blacklist_ratio"), pt.size = 0, ncol = 3)
# remove low-quality cells
crc <- subset(
x = crc,
subset = nCount_peaks > 1000 &
nCount_peaks < 50000 &
pct_reads_in_DNase > 40 &
blacklist_ratio < 0.05 &
TSS.enrichment > 3 &
nucleosome_signal < 4
)
crc## An object of class Seurat
## 81787 features across 1861 samples within 1 assay
## Active assay: peaks (81787 features, 0 variable features)Loading the mitochondrial variant data
Next we can load the mitochondrial DNA variant data for these cells
that was quantified using mgatk. The
ReadMGATK() function in Signac allows the output from
mgatk to be read directly into R in a convenient format for
downstream analysis with Signac. Here, we load the data and add it to
the Seurat object as a new assay.
# load mgatk output
mito.data <- ReadMGATK(dir = "../vignette_data/mito/crc/")
# create an assay
mito <- CreateAssayObject(counts = mito.data$counts)
# Subset to cell present in the scATAC-seq assat
mito <- subset(mito, cells = colnames(crc))
# add assay and metadata to the seurat object
crc[["mito"]] <- mito
crc <- AddMetaData(crc, metadata = mito.data$depth, col.name = "mtDNA_depth")We can look at the mitochondrial sequencing depth for each cell, and further subset the cells based on mitochondrial sequencing depth.
VlnPlot(crc, "mtDNA_depth", pt.size = 0.1) + scale_y_log10()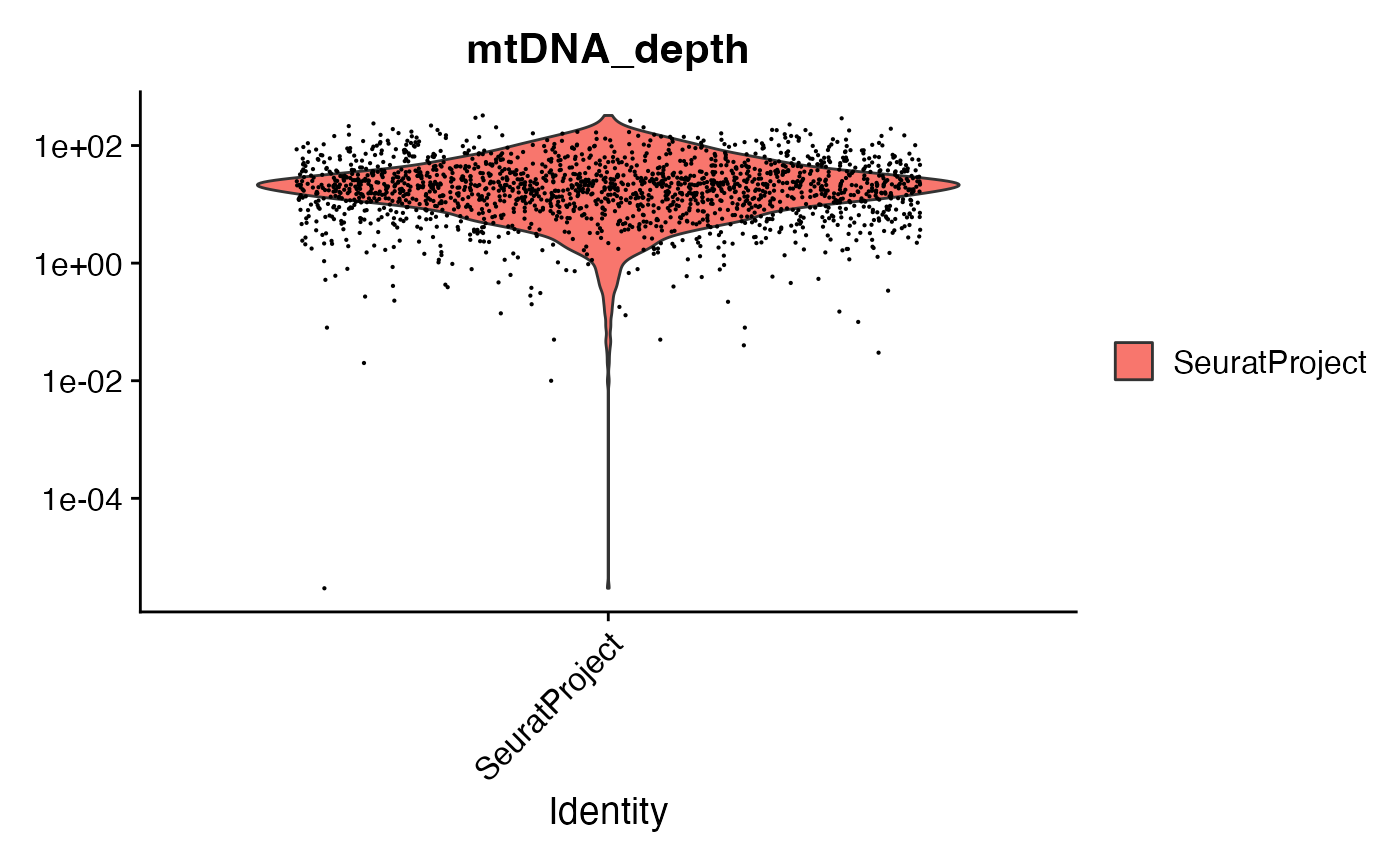
# filter cells based on mitochondrial depth
crc <- subset(crc, mtDNA_depth >= 10)
crc## An object of class Seurat
## 214339 features across 1359 samples within 2 assays
## Active assay: peaks (81787 features, 0 variable features)
## 1 other assay present: mitoDimension reduction and clustering
Next we can run a standard dimension reduction and clustering workflow using the scATAC-seq data to identify cell clusters.
crc <- RunTFIDF(crc)
crc <- FindTopFeatures(crc, min.cutoff = 10)
crc <- RunSVD(crc)
crc <- RunUMAP(crc, reduction = "lsi", dims = 2:50)
crc <- FindNeighbors(crc, reduction = "lsi", dims = 2:50)
crc <- FindClusters(crc, resolution = 0.5, algorithm = 3)## Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
##
## Number of nodes: 1359
## Number of edges: 60801
##
## Running smart local moving algorithm...
## Maximum modularity in 10 random starts: 0.8085
## Number of communities: 6
## Elapsed time: 0 seconds
Generate gene scores
To help interpret these clusters of cells, and assign a cell type label, we’ll estimate gene activities by summing the DNA accessibility in the gene body and promoter region.
# compute gene accessibility
gene.activities <- GeneActivity(crc)
# add to the Seurat object as a new assay
crc[['RNA']] <- CreateAssayObject(counts = gene.activities)
crc <- NormalizeData(
object = crc,
assay = 'RNA',
normalization.method = 'LogNormalize',
scale.factor = median(crc$nCount_RNA)
)Visualize interesting gene activity scores
We note the following markers for different cell types in the CRC dataset:
- EPCAM is a marker for epithelial cells
- TREM1 is a meyloid marker
- PTPRC = CD45 is a pan-immune cell marker
- IL1RL1 is a basophil marker
- GATA3 is a Tcell maker
DefaultAssay(crc) <- 'RNA'
FeaturePlot(
object = crc,
features = c('TREM1', 'EPCAM', "PTPRC", "IL1RL1","GATA3", "KIT"),
pt.size = 0.1,
max.cutoff = 'q95',
ncol = 2
)
Using these gene score values, we can assign cluster identities:
crc <- RenameIdents(
object = crc,
'0' = 'Epithelial',
'1' = 'Epithelial',
'2' = 'Basophil',
'3' = 'Myeloid_1',
'4' = 'Myeloid_2',
'5' = 'Tcell'
)One of the myeloid clusters has a lower percentage of fragments in peaks, as well as a lower overall mitochondrial sequencing depth and a different nucleosome banding pattern.
p1 <- FeatureScatter(crc, "mtDNA_depth", "pct_reads_in_peaks") + ggtitle("") + scale_x_log10()
p2 <- FeatureScatter(crc, "mtDNA_depth", "nucleosome_signal") + ggtitle("") + scale_x_log10()
p1 + p2 + plot_layout(guides = 'collect')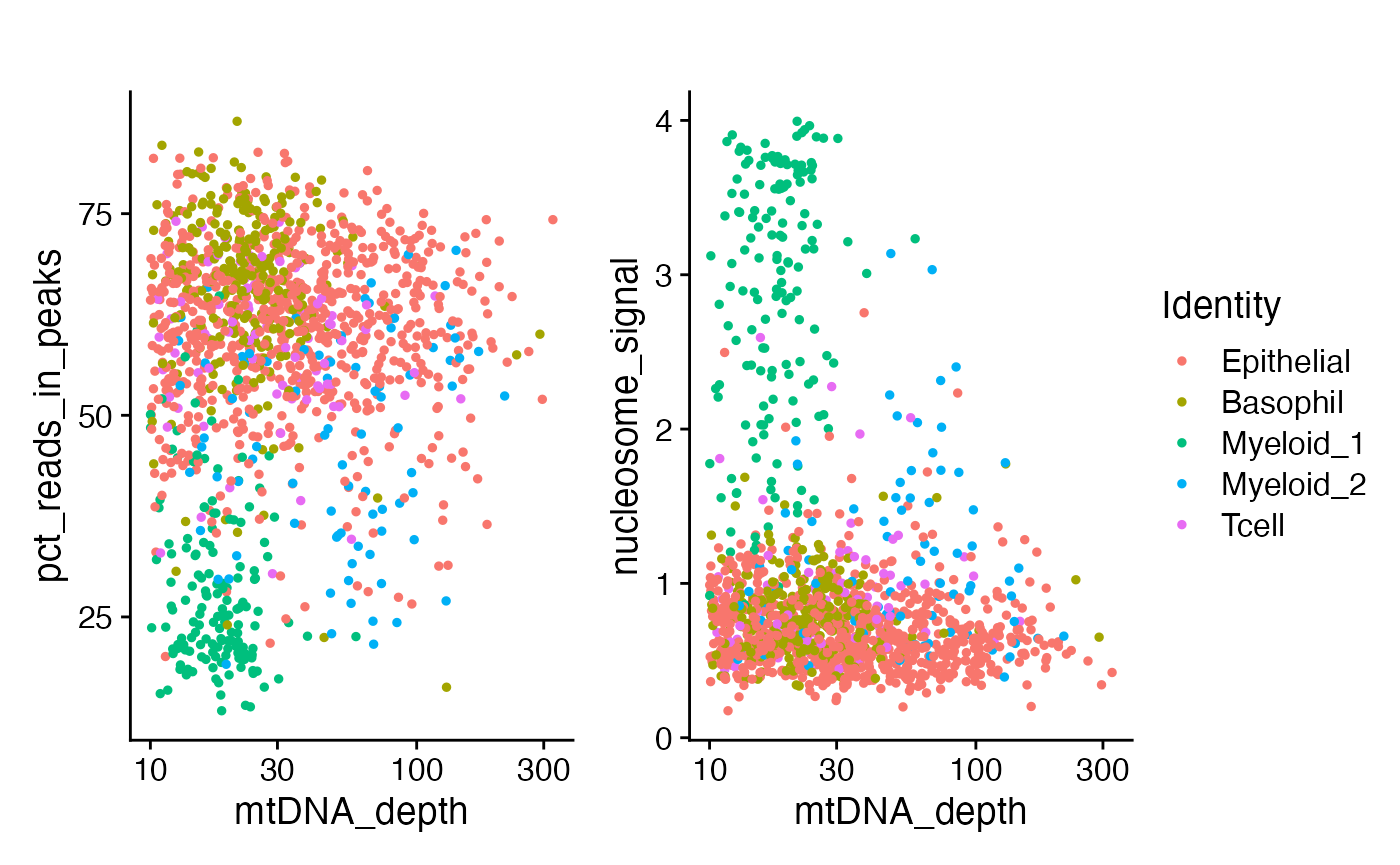
We can see that most of the low FRIP cells were the
myeloid 1 cluster. This is most likely an intra-tumor
granulocyte that has relatively poor accessible chromatin enrichment.
Similarly, the unusual nuclear chromatin packaging of this cell type
yields slightly reduced mtDNA coverage compared to the
myeloid 2 cluster.
Find informative mtDNA variants
Next, we can identify sites in the mitochondrial genome that vary across cells, and cluster the cells into clonotypes based on the frequency of these variants in the cells. Signac utilizes the principles established in the original mtscATAC-seq work of identifying high-quality variants.
variable.sites <- IdentifyVariants(crc, assay = "mito", refallele = mito.data$refallele)
VariantPlot(variants = variable.sites)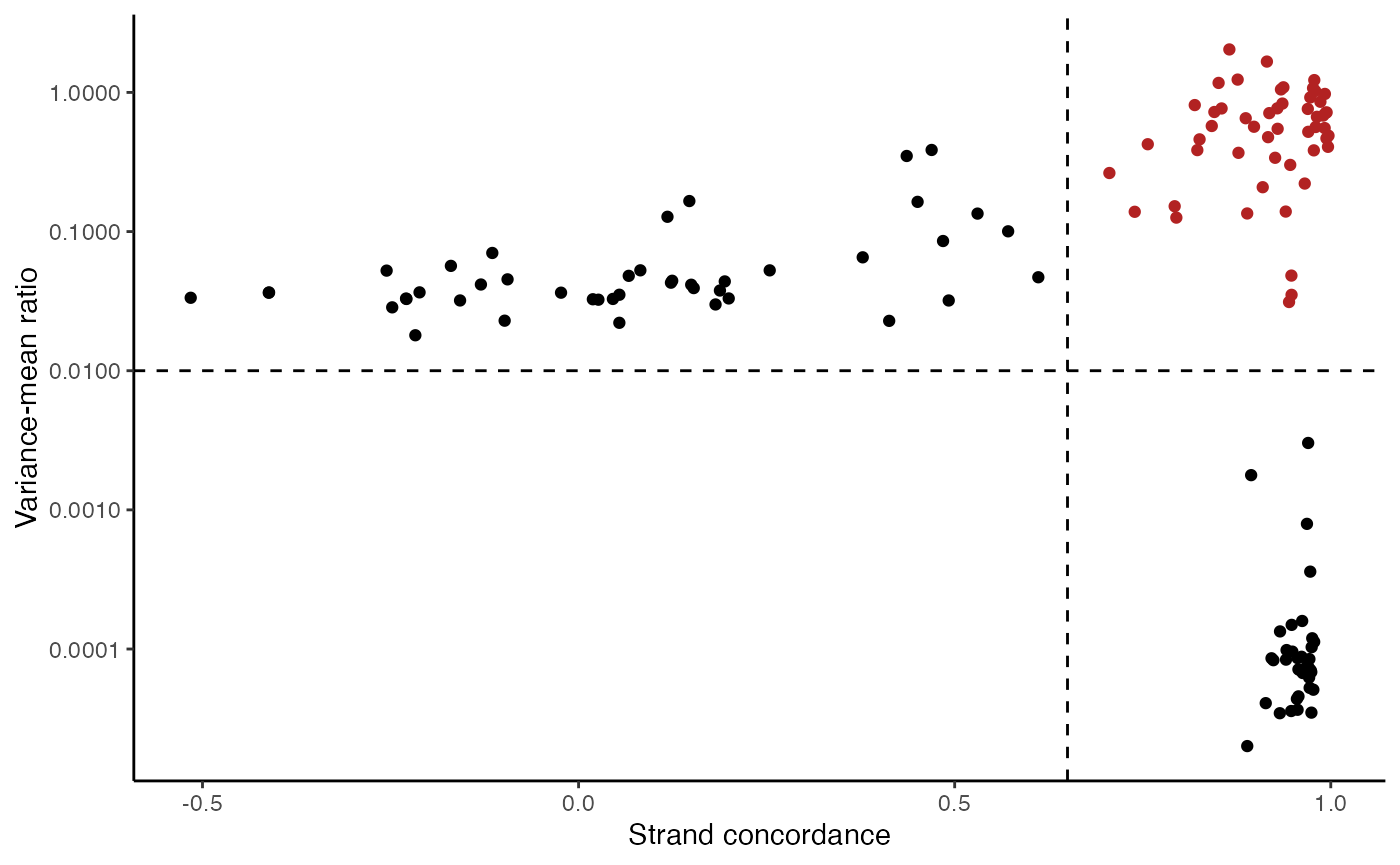
The plot above clearly shows a group of variants with a higher VMR and strand concordance. In principle, a high strand concordance reduces the likelihood of the allele frequency being driven by sequencing error (which predominately occurs on one but not the other strand. This is due to the preceding nucleotide content and a common error in mtDNA genotyping). On the other hand, variants that have a high VMR are more likely to be clonal variants as the alternate alleles tend to aggregate in certain cells rather than be equivalently dispersed about all cells, which would be indicative of some other artifact.
We note that variants that have a very low VMR and and very high strand concordance are homoplasmic variants for this sample. While these may be interesting in some settings (e.g. donor demultiplexing), for inferring subclones, these are not particularly useful.
Based on these thresholds, we can filter out a set of informative mitochondrial variants that differ across the cells.
# Establish a filtered data frame of variants based on this processing
high.conf <- subset(
variable.sites, subset = n_cells_conf_detected >= 5 &
strand_correlation >= 0.65 &
vmr > 0.01
)
high.conf[,c(1,2,5)]## position nucleotide mean
## 1227G>A 1227 G>A 0.0083723
## 6081G>A 6081 G>A 0.0027487
## 9804G>A 9804 G>A 0.0032730
## 12889G>A 12889 G>A 0.0227327
## 9728C>T 9728 C>T 0.0134110
## 16147C>T 16147 C>T 0.6440270
## 824T>C 824 T>C 0.0054583
## 2285T>C 2285 T>C 0.0055419
## 9840T>C 9840 T>C 0.0021322
## 16093T>C 16093 T>C 0.0079506A few things stand out. First, 10 out of the 12 variants occur at less than 1% allele frequency in the population. However, 16147C>T is present at about 62%. We’ll see that this is a clonal variant marking the epithelial cells. Additionally, all of the called variants are transitions (A - G or C - T) rather than transversion mutations (A - T or C - G). This fits what we know about how these mutations arise in the mitochondrial genome.
Depending on your analytical question, these thresholds can be adjusted to identify variants that are more prevalent in other cells.
Compute the variant allele frequency for each cell
We currently have information for each strand stored in the mito
assay to allow strand concordance to be assessed. Now that we have our
set of high-confidence informative variants, we can create a new assay
containing strand-collapsed allele frequency counts for each cell for
these variants using the AlleleFreq() function.
crc <- AlleleFreq(
object = crc,
variants = high.conf$variant,
assay = "mito"
)
crc[["alleles"]]## Assay data with 10 features for 1359 cells
## First 10 features:
## 1227G>A, 6081G>A, 9804G>A, 12889G>A, 9728C>T, 16147C>T, 824T>C,
## 2285T>C, 9840T>C, 16093T>CVisualize the variants
Now that the allele frequencies are stored as an additional assay, we
can use the standard functions in Seurat to visualize how these allele
frequencies are distributed across the cells. Here we visualize a subset
of the variants using FeaturePlot() and
DoHeatmap().
DefaultAssay(crc) <- "alleles"
alleles.view <- c("12889G>A", "16147C>T", "9728C>T", "9804G>A")
FeaturePlot(
object = crc,
features = alleles.view,
order = TRUE,
cols = c("grey", "darkred"),
ncol = 4
) & NoLegend()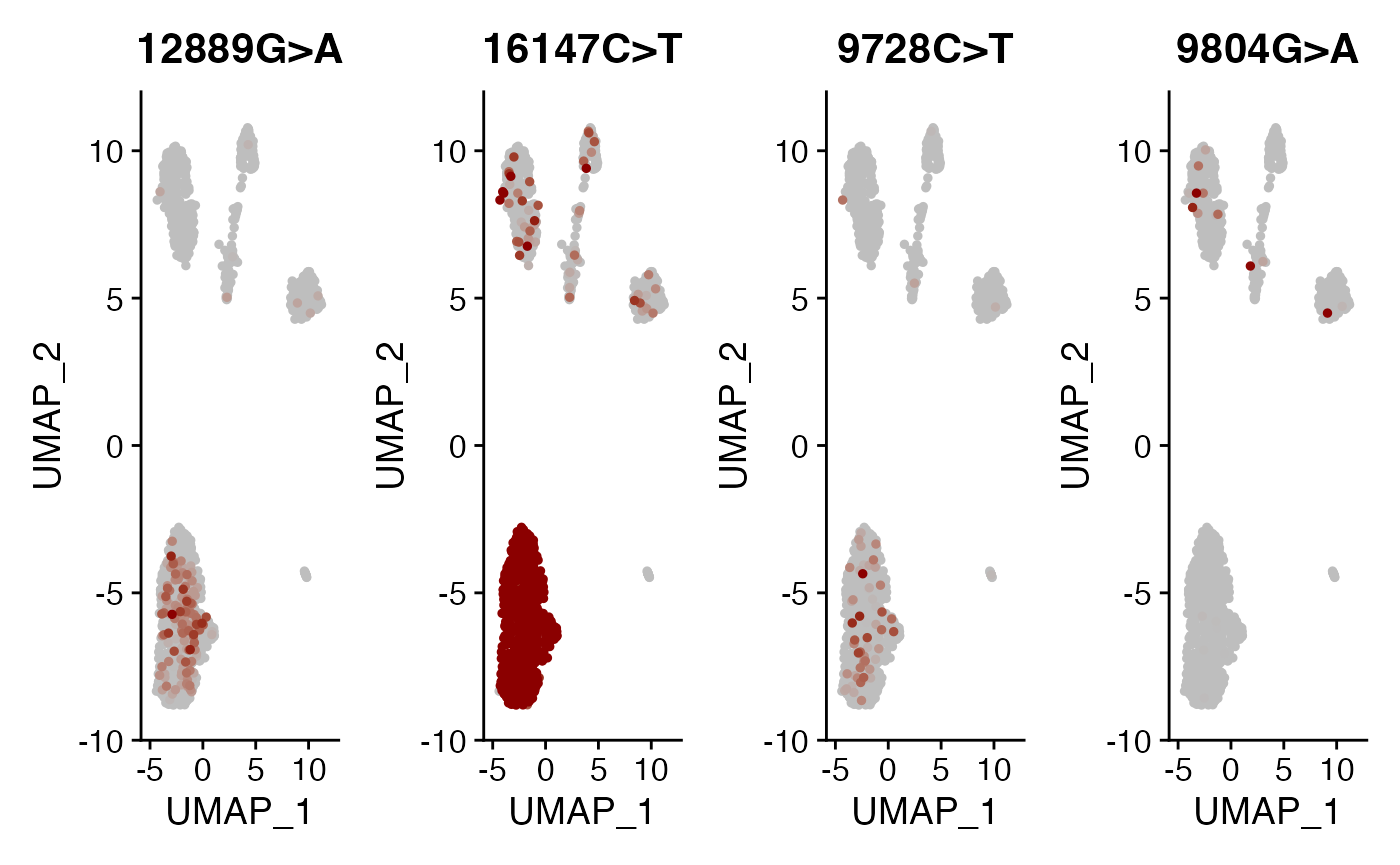
DoHeatmap(crc, features = rownames(crc), slot = "data", disp.max = 1) +
scale_fill_viridis_c()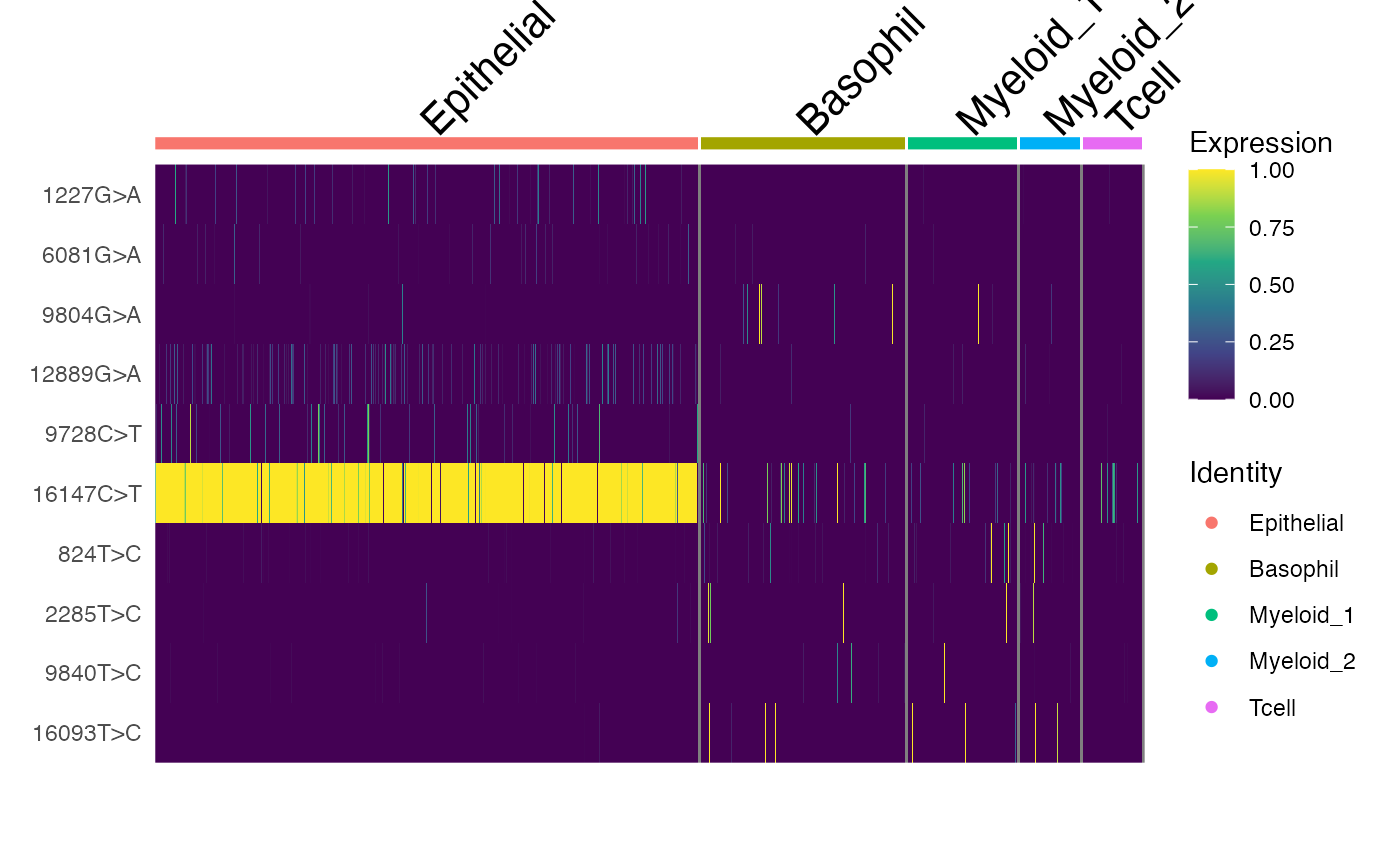
Here, we can see a few interesting patterns for the selected variants. 16147C>T is present in essentially all epithelial cells and almost exclusively in epithelial cells (the edge cases where this isn’t true are also cases where the UMAP and clustering don’t full agree). It is at 100% allele frequency– strongly suggestive of whatever cell of origin of this tumor had the mutation at 100% and then expanded. We then see at least 3 variants 1227G>A, 12889G>A, and 9728C>T that are mostly present specifically in the epithelial cells that define subclones. Other variants including 3244G>A, 9804G>A, and 824T>C are found specifically in immune cell populations, suggesting that these arose from a common hematopoetic progenitor cell (probably in the bone marrow).
TF1 cell line dataset
Next we’ll demonstrate a similar workflow to identify cell clones in a different dataset, this time generated from a TF1 cell line. This dataset contains more clones present at a higher proportion, based on the experimental design.
We’ll demonstrate how to identify groups of related cells (clones) by clustering the allele frequency data and how to relate these clonal groups to accessibility differences utilizing the multimodal capabilities of Signac.
Data loading
View data download code
To download the data from Zenodo run the following in a shell:
# ATAC data
wget https://zenodo.org/record/3977808/files/TF1.filtered.fragments.tsv.gz
wget https://zenodo.org/record/3977808/files/TF1.filtered.fragments.tsv.gz.tbi
wget https://zenodo.org/record/3977808/files/TF1.filtered.narrowPeak.gz
# mitochondrial genome data
wget https://zenodo.org/record/3977808/files/TF1_filtered.A.txt.gz
wget https://zenodo.org/record/3977808/files/TF1_filtered.T.txt.gz
wget https://zenodo.org/record/3977808/files/TF1_filtered.C.txt.gz
wget https://zenodo.org/record/3977808/files/TF1_filtered.G.txt.gz
wget https://zenodo.org/record/3977808/files/TF1_filtered.chrM_refAllele.txt.gz
wget https://zenodo.org/record/3977808/files/TF1_filtered.depthTable.txt.gz
# read the mitochondrial data
tf1.data <- ReadMGATK(dir = "../vignette_data/mito/tf1/")## Reading allele counts## Reading metadata## Building matrices
# create a Seurat object
tf1 <- CreateSeuratObject(
counts = tf1.data$counts,
meta.data = tf1.data$depth,
assay = "mito"
)
# load the peak set
peaks <- read.table(
file = "../vignette_data/mito/TF1.filtered.narrowPeak.gz",
sep = "\t",
col.names = c("chrom", "start", "end", "peak", "width", "strand", "x", "y", "z", "w")
)
peaks <- makeGRangesFromDataFrame(peaks)
# create fragment object
frags <- CreateFragmentObject(
path = "../vignette_data/mito/TF1.filtered.fragments.tsv.gz",
cells = colnames(tf1)
)## Computing hash
# quantify the DNA accessibility data
counts <- FeatureMatrix(
fragments = frags,
features = peaks,
cells = colnames(tf1)
)## Extracting reads overlapping genomic regions
# create assay with accessibility data and add it to the Seurat object
tf1[["peaks"]] <- CreateChromatinAssay(
counts = counts,
fragments = frags
)Quality control
# add annotations
Annotation(tf1[["peaks"]]) <- annotations
DefaultAssay(tf1) <- "peaks"
tf1 <- NucleosomeSignal(tf1)
tf1 <- TSSEnrichment(tf1)
tf1 <- subset(
x = tf1,
subset = nCount_peaks > 500 &
nucleosome_signal < 2 &
TSS.enrichment > 2.5
)
tf1## An object of class Seurat
## 255300 features across 832 samples within 2 assays
## Active assay: peaks (122748 features, 0 variable features)
## 1 other assay present: mitoIdentifying variants
DefaultAssay(tf1) <- "mito"
variants <- IdentifyVariants(tf1, refallele = tf1.data$refallele)## Computing total coverage per base## Processing A## Processing T## Processing C## Processing G
VariantPlot(variants)
high.conf <- subset(
variants, subset = n_cells_conf_detected >= 5 &
strand_correlation >= 0.65 &
vmr > 0.01
)
tf1 <- AlleleFreq(tf1, variants = high.conf$variant, assay = "mito")
tf1[["alleles"]]## Assay data with 51 features for 832 cells
## First 10 features:
## 627G>A, 709G>A, 1045G>A, 1793G>A, 1888G>A, 1906G>A, 2002G>A, 2040G>A,
## 2573G>A, 2643G>AIdentifying clones
Now that we’ve identified a set of variable alleles, we can cluster
the cells based on the frequency of each of these alleles using the
FindClonotypes() function. This uses the Louvain community
detection algorithm implemented in Seurat.
DefaultAssay(tf1) <- "alleles"
tf1 <- FindClonotypes(tf1)## Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
##
## Number of nodes: 832
## Number of edges: 15680
##
## Running smart local moving algorithm...
## Maximum modularity in 10 random starts: 0.8398
## Number of communities: 12
## Elapsed time: 0 seconds##
## 10 11 9 4 7 8 2 3 1 5 0 6
## 17 11 23 107 32 30 116 107 123 80 153 33Here we see that the clonal clustering has identified 12 different
clones in the TF1 dataset. We can further visualize the frequency of
alleles in these clones using DoHeatmap(). The
FindClonotypes() function also performs hierarchical
clustering on both the clonotypes and the alleles, and sets the factor
levels for the clonotypes based on the hierarchical clustering order,
and the order of variable features based on the hierarchical feature
clustering. This allows us to get a decent ordering of both features and
clones automatically:
DoHeatmap(tf1, features = VariableFeatures(tf1), slot = "data", disp.max = 0.1) +
scale_fill_viridis_c()
Find differentially accessible peaks between clones
Next we can use the clonal information derived from the mitochondrial assay to find peaks that are differentially accessible between clones.
DefaultAssay(tf1) <- "peaks"
# find peaks specific to one clone
markers.fast <- FoldChange(tf1, ident.1 = 2)
markers.fast <- markers.fast[order(markers.fast$avg_log2FC, decreasing = TRUE), ] # sort by fold change
head(markers.fast)## avg_log2FC pct.1 pct.2
## chr5-42811975-42812177 3.801568 0.164 0.014
## chr3-4061278-4061591 3.725423 0.172 0.018
## chr5-44130972-44131478 3.666023 0.267 0.038
## chr5-43874930-43875314 3.447547 0.284 0.029
## chr5-42591230-42591506 3.413157 0.172 0.014
## chr6-114906484-114906735 3.271312 0.147 0.018We can the DNA accessibility in these regions for each clone using
the CoveragePlot() function. As you can see, the peaks
identified are highly specific to one clone.
CoveragePlot(
object = tf1,
region = rownames(markers.fast)[1],
extend.upstream = 2000,
extend.downstream = 2000
)## Warning: Removed 47 rows containing missing values (`geom_segment()`).## Warning: Removed 1 rows containing missing values (`geom_segment()`).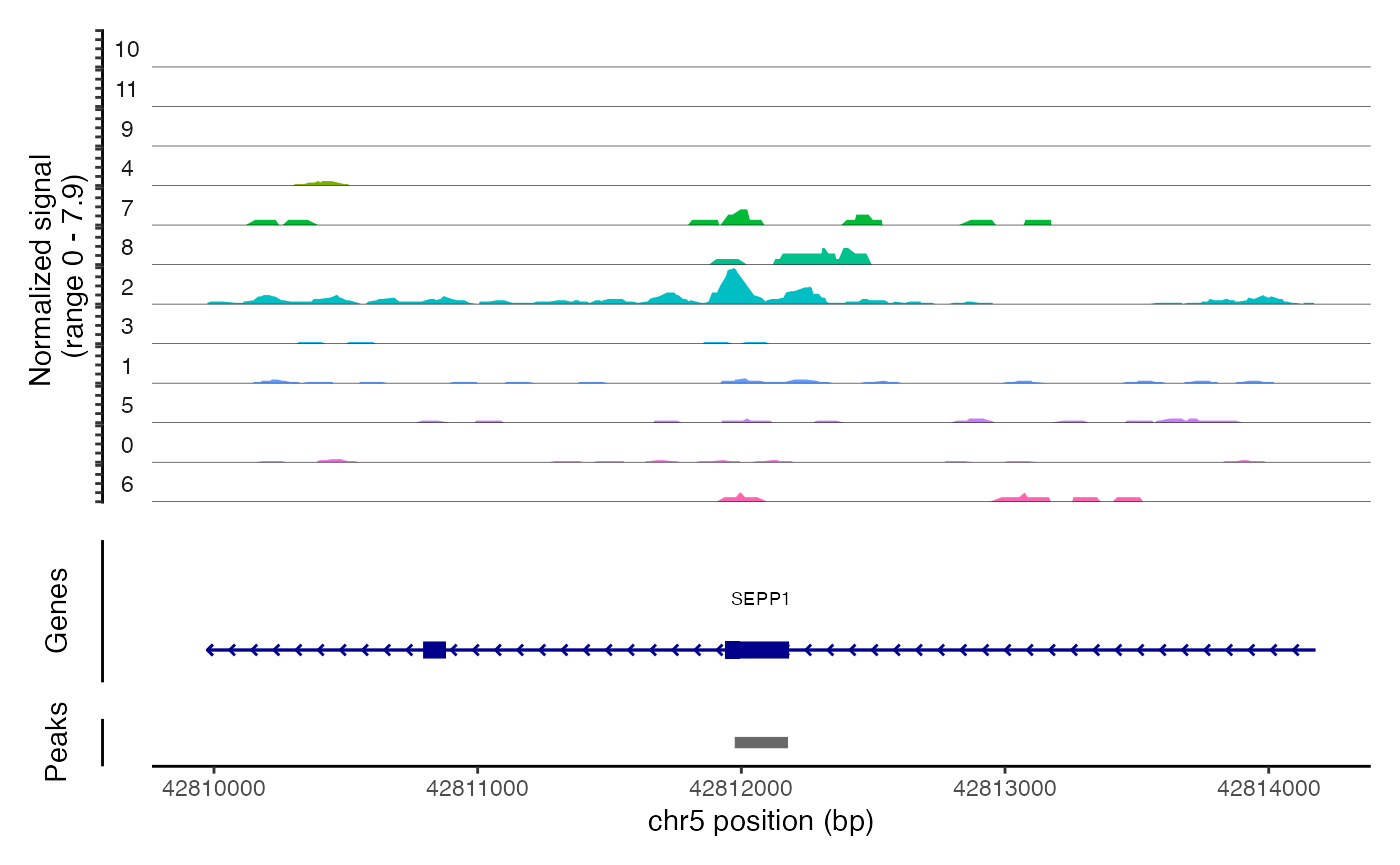
Session Info
## R version 4.3.1 (2023-06-16)
## Platform: aarch64-apple-darwin20 (64-bit)
## Running under: macOS Sonoma 14.0
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## time zone: Asia/Singapore
## tzcode source: internal
##
## attached base packages:
## [1] stats4 stats graphics grDevices utils datasets methods
## [8] base
##
## other attached packages:
## [1] EnsDb.Hsapiens.v75_2.99.0 ensembldb_2.24.1
## [3] AnnotationFilter_1.24.0 GenomicFeatures_1.52.2
## [5] AnnotationDbi_1.62.2 Biobase_2.60.0
## [7] GenomicRanges_1.52.0 GenomeInfoDb_1.36.3
## [9] IRanges_2.34.1 S4Vectors_0.38.2
## [11] BiocGenerics_0.46.0 patchwork_1.1.3
## [13] ggplot2_3.4.4 SeuratObject_4.1.4
## [15] Seurat_4.4.0 Signac_1.11.0
##
## loaded via a namespace (and not attached):
## [1] fs_1.6.3 ProtGenerics_1.32.0
## [3] matrixStats_1.0.0 spatstat.sparse_3.0-2
## [5] bitops_1.0-7 httr_1.4.7
## [7] RColorBrewer_1.1-3 tools_4.3.1
## [9] sctransform_0.4.0 backports_1.4.1
## [11] utf8_1.2.3 R6_2.5.1
## [13] lazyeval_0.2.2 uwot_0.1.16
## [15] withr_2.5.1 sp_2.1-0
## [17] prettyunits_1.2.0 gridExtra_2.3
## [19] progressr_0.14.0 cli_3.6.1
## [21] textshaping_0.3.7 spatstat.explore_3.2-3
## [23] labeling_0.4.3 sass_0.4.7
## [25] spatstat.data_3.0-1 ggridges_0.5.4
## [27] pbapply_1.7-2 pkgdown_2.0.7
## [29] Rsamtools_2.16.0 systemfonts_1.0.5
## [31] foreign_0.8-84 dichromat_2.0-0.1
## [33] parallelly_1.36.0 BSgenome_1.68.0
## [35] rstudioapi_0.15.0 RSQLite_2.3.1
## [37] generics_0.1.3 BiocIO_1.10.0
## [39] ica_1.0-3 spatstat.random_3.1-6
## [41] dplyr_1.1.3 Matrix_1.6-1.1
## [43] ggbeeswarm_0.7.2 fansi_1.0.5
## [45] abind_1.4-5 lifecycle_1.0.3
## [47] yaml_2.3.7 SummarizedExperiment_1.30.2
## [49] BiocFileCache_2.8.0 Rtsne_0.16
## [51] grid_4.3.1 blob_1.2.4
## [53] promises_1.2.1 crayon_1.5.2
## [55] miniUI_0.1.1.1 lattice_0.21-8
## [57] cowplot_1.1.1 KEGGREST_1.40.1
## [59] pillar_1.9.0 knitr_1.44
## [61] rjson_0.2.21 future.apply_1.11.0
## [63] codetools_0.2-19 fastmatch_1.1-4
## [65] leiden_0.4.3 glue_1.6.2
## [67] data.table_1.14.8 vctrs_0.6.3
## [69] png_0.1-8 gtable_0.3.4
## [71] cachem_1.0.8 xfun_0.40
## [73] S4Arrays_1.0.6 mime_0.12
## [75] survival_3.5-5 RcppRoll_0.3.0
## [77] ellipsis_0.3.2 fitdistrplus_1.1-11
## [79] ROCR_1.0-11 lsa_0.73.3
## [81] nlme_3.1-162 bit64_4.0.5
## [83] progress_1.2.2 filelock_1.0.2
## [85] RcppAnnoy_0.0.21 rprojroot_2.0.3
## [87] SnowballC_0.7.1 bslib_0.5.1
## [89] irlba_2.3.5.1 vipor_0.4.5
## [91] KernSmooth_2.23-21 rpart_4.1.19
## [93] colorspace_2.1-0 DBI_1.1.3
## [95] Hmisc_5.1-1 nnet_7.3-19
## [97] ggrastr_1.0.2 tidyselect_1.2.0
## [99] bit_4.0.5 compiler_4.3.1
## [101] curl_5.1.0 htmlTable_2.4.1
## [103] hdf5r_1.3.8 xml2_1.3.5
## [105] desc_1.4.2 DelayedArray_0.26.7
## [107] plotly_4.10.2 rtracklayer_1.60.1
## [109] checkmate_2.2.0 scales_1.2.1
## [111] lmtest_0.9-40 rappdirs_0.3.3
## [113] stringr_1.5.0 digest_0.6.33
## [115] goftest_1.2-3 spatstat.utils_3.0-3
## [117] rmarkdown_2.25 XVector_0.40.0
## [119] htmltools_0.5.6.1 pkgconfig_2.0.3
## [121] base64enc_0.1-3 MatrixGenerics_1.12.3
## [123] dbplyr_2.3.4 fastmap_1.1.1
## [125] rlang_1.1.1 htmlwidgets_1.6.2
## [127] shiny_1.7.5 farver_2.1.1
## [129] jquerylib_0.1.4 zoo_1.8-12
## [131] jsonlite_1.8.7 BiocParallel_1.34.2
## [133] VariantAnnotation_1.46.0 RCurl_1.98-1.12
## [135] magrittr_2.0.3 Formula_1.2-5
## [137] GenomeInfoDbData_1.2.10 munsell_0.5.0
## [139] Rcpp_1.0.11 reticulate_1.32.0
## [141] stringi_1.7.12 zlibbioc_1.46.0
## [143] MASS_7.3-60 plyr_1.8.9
## [145] parallel_4.3.1 listenv_0.9.0
## [147] ggrepel_0.9.3 deldir_1.0-9
## [149] Biostrings_2.68.1 splines_4.3.1
## [151] tensor_1.5 hms_1.1.3
## [153] igraph_1.5.1 spatstat.geom_3.2-5
## [155] reshape2_1.4.4 biomaRt_2.56.1
## [157] XML_3.99-0.14 evaluate_0.22
## [159] biovizBase_1.48.0 httpuv_1.6.11
## [161] RANN_2.6.1 tidyr_1.3.0
## [163] purrr_1.0.2 polyclip_1.10-6
## [165] future_1.33.0 scattermore_1.2
## [167] xtable_1.8-4 restfulr_0.0.15
## [169] later_1.3.1 viridisLite_0.4.2
## [171] ragg_1.2.6 tibble_3.2.1
## [173] memoise_2.0.1 beeswarm_0.4.0
## [175] GenomicAlignments_1.36.0 cluster_2.1.4
## [177] globals_0.16.2