Motif analysis with Signac
Compiled: October 13, 2023
Source:vignettes/motif_vignette.Rmd
motif_vignette.RmdIn this tutorial, we will perform DNA sequence motif analysis in Signac. We will explore two complementary options for performing motif analysis: one by finding overrepresented motifs in a set of differentially accessible peaks, one method performing differential motif activity analysis between groups of cells.
In this demonstration we use data from the adult mouse brain. See our vignette for the code used to generate this object, and links to the raw data. First, load the required packages and the pre-computed Seurat object:
library(Signac)
library(Seurat)
library(JASPAR2020)
library(TFBSTools)
library(BSgenome.Mmusculus.UCSC.mm10)
library(patchwork)
mouse_brain <- readRDS("../vignette_data/adult_mouse_brain.rds")
mouse_brain## An object of class Seurat
## 179011 features across 3512 samples within 2 assays
## Active assay: peaks (157203 features, 157203 variable features)
## 1 other assay present: RNA
## 2 dimensional reductions calculated: lsi, umap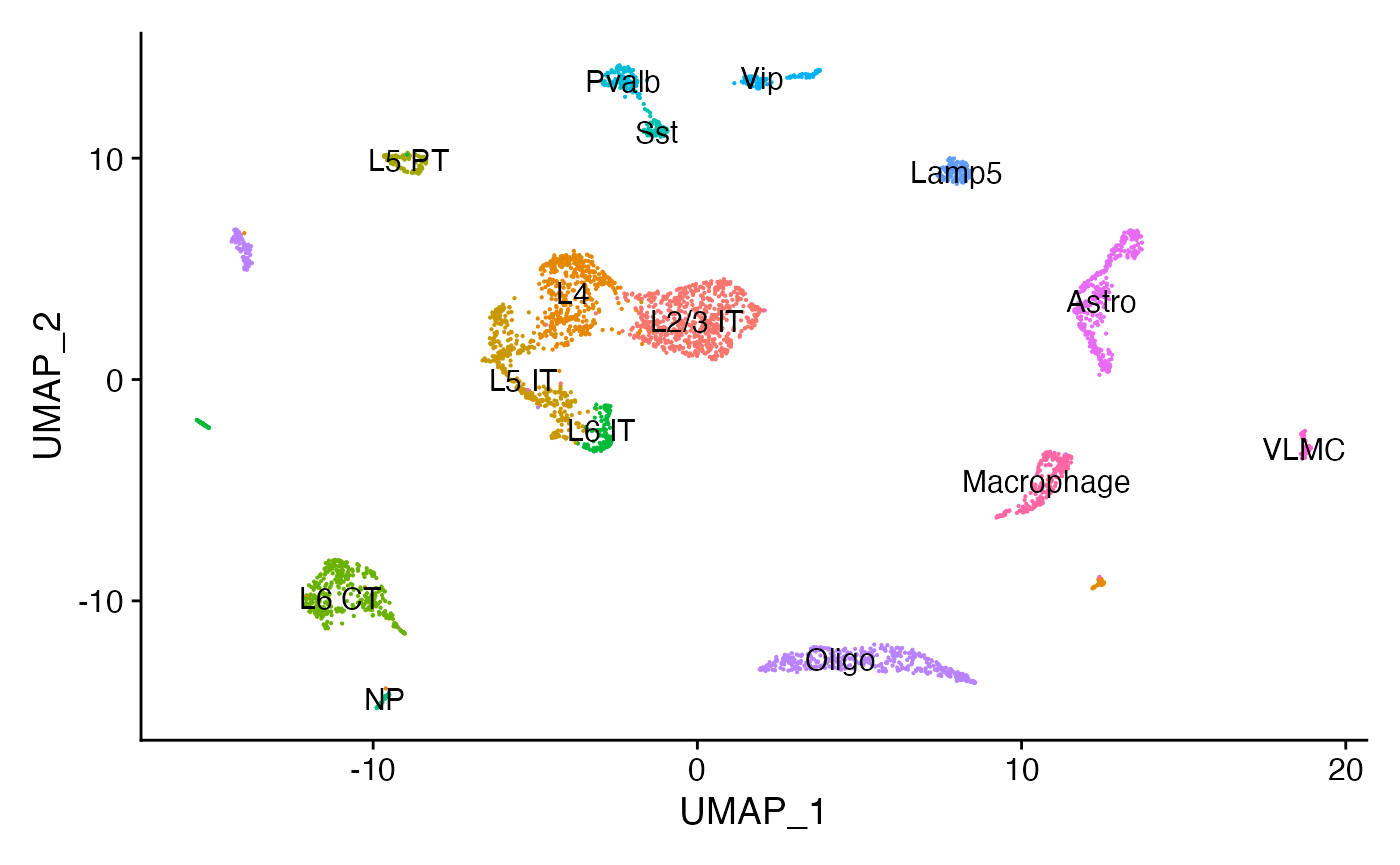
Adding motif information to the Seurat object
To add the DNA sequence motif information required for motif
analyses, we can run the AddMotifs() function:
# Get a list of motif position frequency matrices from the JASPAR database
pfm <- getMatrixSet(
x = JASPAR2020,
opts = list(collection = "CORE", tax_group = 'vertebrates', all_versions = FALSE)
)
# add motif information
mouse_brain <- AddMotifs(
object = mouse_brain,
genome = BSgenome.Mmusculus.UCSC.mm10,
pfm = pfm
)To facilitate motif analysis in Signac, we have created the
Motif class to store all the required information,
including a list of position weight matrices (PWMs) or position
frequency matrices (PFMs) and a motif occurrence matrix. Here, the
AddMotifs() function constructs a Motif object
and adds it to our mouse brain dataset, along with other information
such as the base composition of each peak. A motif object can be added
to any Seurat assay using the SetAssayData() function. See
the object interaction vignette for
more information.
Finding overrepresented motifs
To identify potentially important cell-type-specific regulatory sequences, we can search for DNA motifs that are overrepresented in a set of peaks that are differentially accessible between cell types.
Here, we find differentially accessible peaks between Pvalb and Sst
inhibitory interneurons. For sparse data (such as scATAC-seq), we find
it is often necessary to lower the min.pct threshold in
FindMarkers() from the default (0.1, which was designed for
scRNA-seq data).
We then perform a hypergeometric test to test the probability of observing the motif at the given frequency by chance, comparing with a background set of peaks matched for GC content.
da_peaks <- FindMarkers(
object = mouse_brain,
ident.1 = 'Pvalb',
ident.2 = 'Sst',
only.pos = TRUE,
test.use = 'LR',
min.pct = 0.05,
latent.vars = 'nCount_peaks'
)
# get top differentially accessible peaks
top.da.peak <- rownames(da_peaks[da_peaks$p_val < 0.005, ])Optional: choosing a set of background peaks
Matching the set of background peaks is essential when finding enriched DNA sequence motifs. By default, we choose a set of peaks matched for GC content, but it can be sometimes be beneficial to further restrict the background peaks to those that are accessible in the groups of cells compared when finding differentially accessible peaks.
The AccessiblePeaks() function can be used to find a set
of peaks that are open in a subset of cells. We can use this function to
first restrict the set of possible background peaks to those peaks that
were open in the set of cells compared in FindMarkers(),
and then create a GC-content-matched set of peaks from this larger set
using MatchRegionStats().
# find peaks open in Pvalb or Sst cells
open.peaks <- AccessiblePeaks(mouse_brain, idents = c("Pvalb", "Sst"))
# match the overall GC content in the peak set
meta.feature <- GetAssayData(mouse_brain, assay = "peaks", slot = "meta.features")
peaks.matched <- MatchRegionStats(
meta.feature = meta.feature[open.peaks, ],
query.feature = meta.feature[top.da.peak, ],
n = 50000
)## Matching GC.percent distributionpeaks.matched can then be used as the background peak
set by setting background=peaks.matched in
FindMotifs().
# test enrichment
enriched.motifs <- FindMotifs(
object = mouse_brain,
features = top.da.peak
)## Selecting background regions to match input sequence characteristics## Matching GC.percent distribution## Testing motif enrichment in 2727 regions| motif | observed | background | percent.observed | percent.background | fold.enrichment | pvalue | motif.name | p.adjust | |
|---|---|---|---|---|---|---|---|---|---|
| MA0497.1 | MA0497.1 | 1162 | 8912 | 42.61093 | 22.2800 | 1.912519 | 0 | MEF2C | 0 |
| MA0052.4 | MA0052.4 | 1092 | 8609 | 40.04400 | 21.5225 | 1.860565 | 0 | MEF2A | 0 |
| MA0773.1 | MA0773.1 | 785 | 5320 | 28.78621 | 13.3000 | 2.164377 | 0 | MEF2D | 0 |
| MA1151.1 | MA1151.1 | 570 | 3209 | 20.90209 | 8.0225 | 2.605434 | 0 | RORC | 0 |
| MA1150.1 | MA1150.1 | 543 | 3073 | 19.91199 | 7.6825 | 2.591864 | 0 | RORB | 0 |
| MA0660.1 | MA0660.1 | 665 | 4261 | 24.38577 | 10.6525 | 2.289207 | 0 | MEF2B | 0 |
We can also plot the position weight matrices for the motifs, so we can visualize the different motif sequences.
## Warning: The `<scale>` argument of `guides()` cannot be `FALSE`. Use "none" instead as
## of ggplot2 3.3.4.
## ℹ The deprecated feature was likely used in the ggseqlogo package.
## Please report the issue at <https://github.com/omarwagih/ggseqlogo/issues>.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.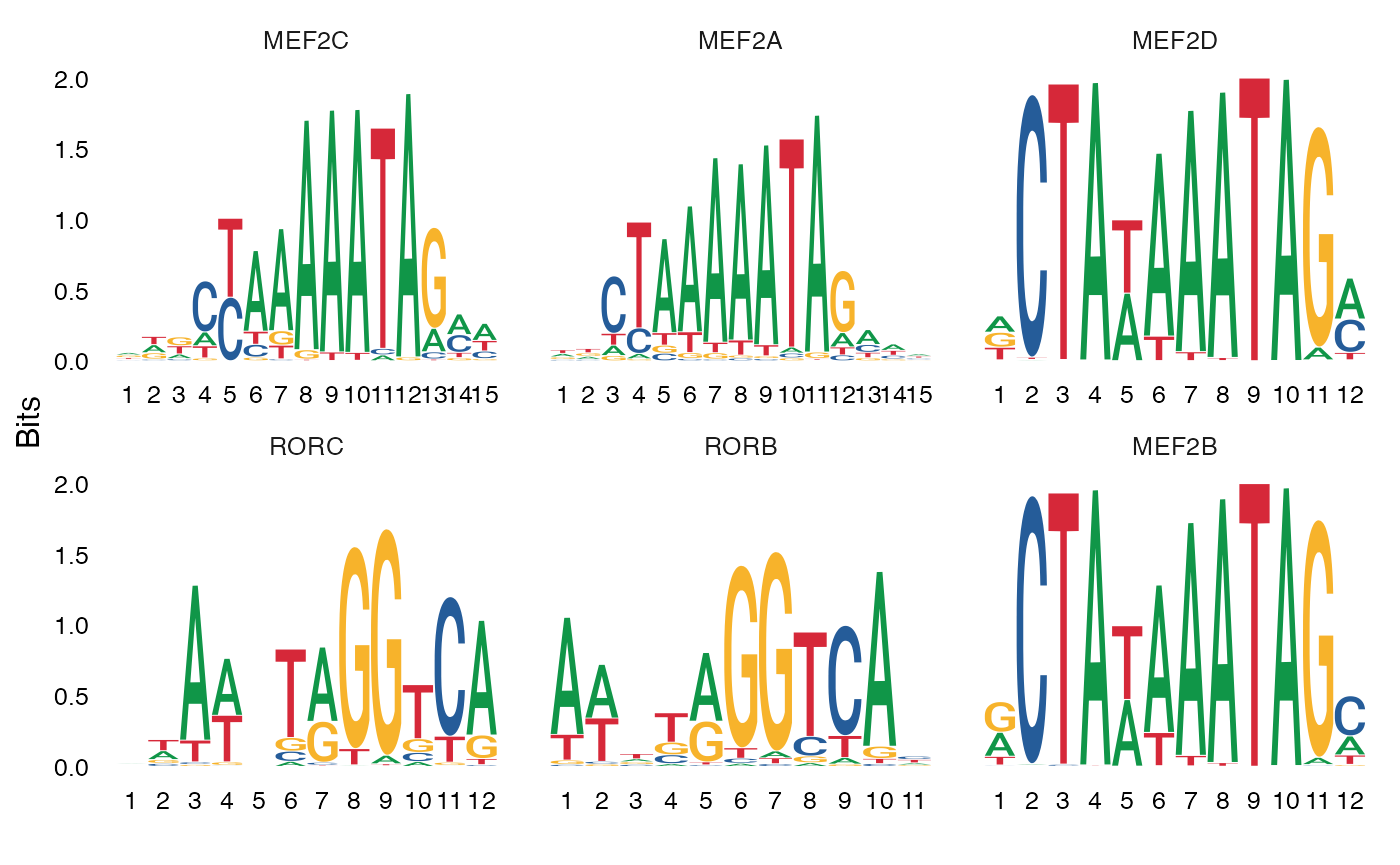
We and others have previously shown that Mef-family motifs,
particularly Mef2c, are enriched in Pvalb-specific peaks in
scATAC-seq data (https://doi.org/10.1016/j.cell.2019.05.031; https://doi.org/10.1101/615179), and further shown that
Mef2c is required for the development of Pvalb interneurons (https://www.nature.com/articles/nature25999). Here our
results are consistent with these findings, and we observe a strong
enrichment of Mef-family motifs in the top results from
FindMotifs().
Computing motif activities
We can also compute a per-cell motif activity score by running chromVAR. This allows us to visualize motif activities per cell, and also provides an alternative method of identifying differentially-active motifs between cell types.
ChromVAR identifies motifs associated with variability in chromatin accessibility between cells. See the chromVAR paper for a complete description of the method.
mouse_brain <- RunChromVAR(
object = mouse_brain,
genome = BSgenome.Mmusculus.UCSC.mm10
)
DefaultAssay(mouse_brain) <- 'chromvar'
# look at the activity of Mef2c
p2 <- FeaturePlot(
object = mouse_brain,
features = "MA0497.1",
min.cutoff = 'q10',
max.cutoff = 'q90',
pt.size = 0.1
)
p1 + p2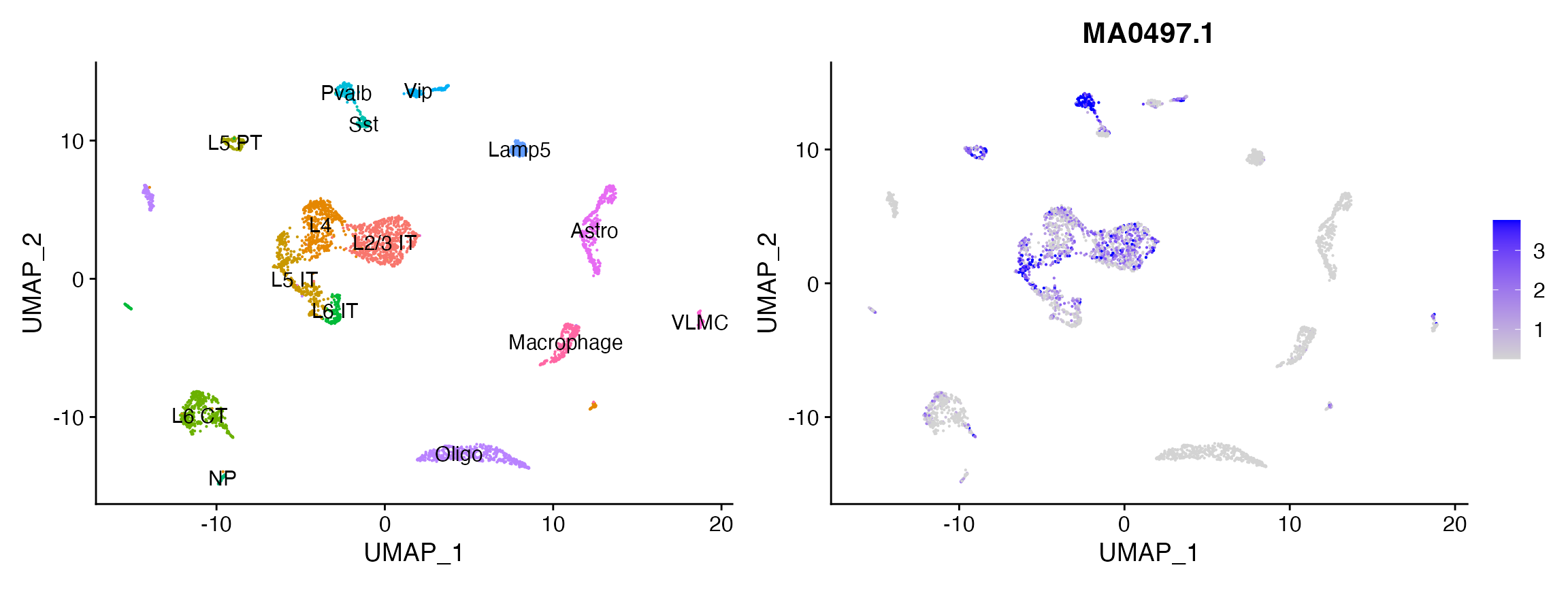
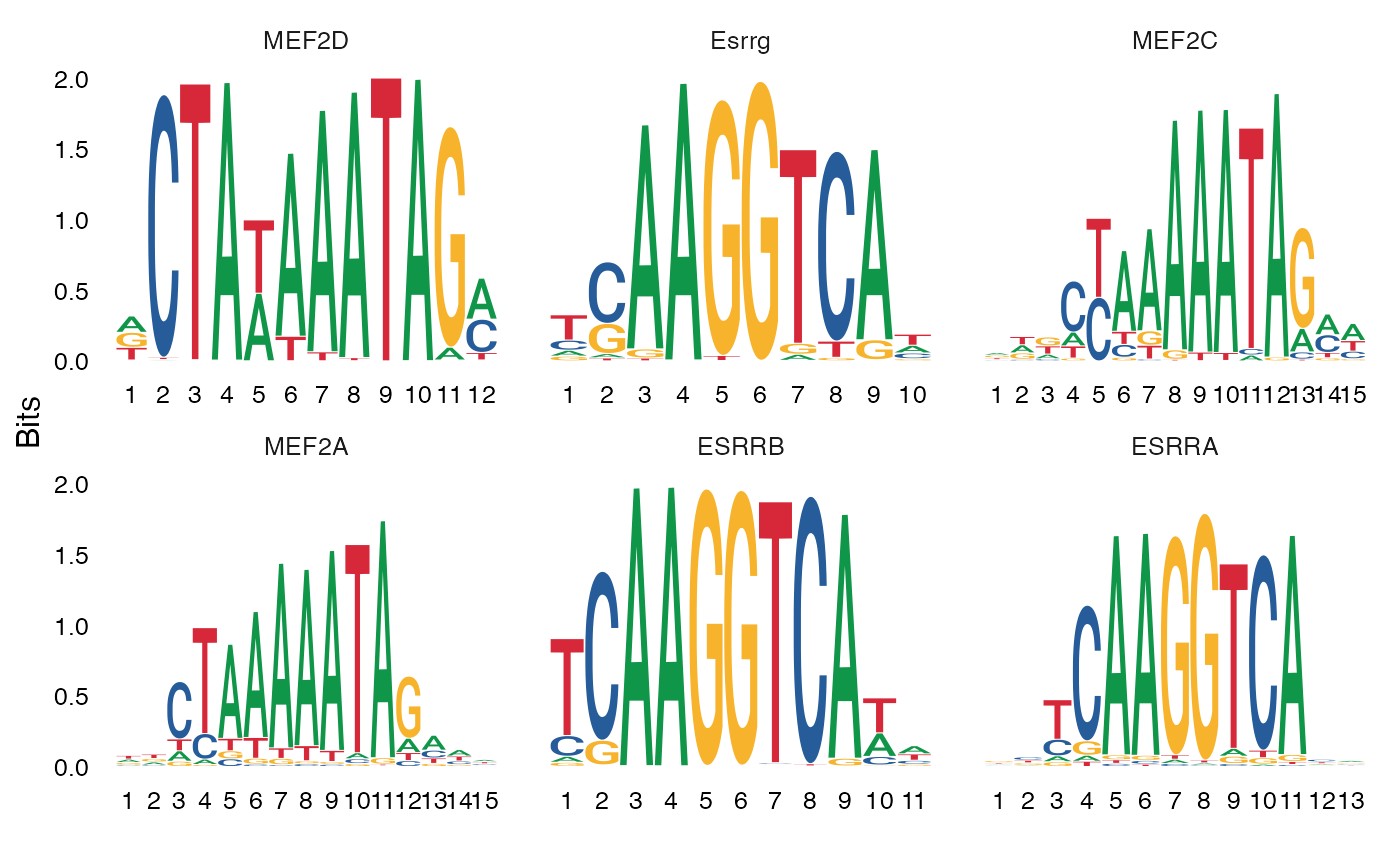
We can also directly test for differential activity scores between cell types. This tends to give similar results as performing an enrichment test on differentially accessible peaks between the cell types (shown above).
When performing differential testing on the chromVAR z-score, we can
set mean.fxn=rowMeans and fc.name="avg_diff"
in the FindMarkers() function so that the fold-change
calculation computes the average difference in z-score between the
groups.
differential.activity <- FindMarkers(
object = mouse_brain,
ident.1 = 'Pvalb',
ident.2 = 'Sst',
only.pos = TRUE,
mean.fxn = rowMeans,
fc.name = "avg_diff"
)
MotifPlot(
object = mouse_brain,
motifs = head(rownames(differential.activity)),
assay = 'peaks'
)
Session Info
## R version 4.3.1 (2023-06-16)
## Platform: aarch64-apple-darwin20 (64-bit)
## Running under: macOS Sonoma 14.0
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## time zone: Asia/Singapore
## tzcode source: internal
##
## attached base packages:
## [1] stats4 stats graphics grDevices utils datasets methods
## [8] base
##
## other attached packages:
## [1] patchwork_1.1.3 BSgenome.Mmusculus.UCSC.mm10_1.4.3
## [3] BSgenome_1.68.0 rtracklayer_1.60.1
## [5] Biostrings_2.68.1 XVector_0.40.0
## [7] GenomicRanges_1.52.0 GenomeInfoDb_1.36.3
## [9] IRanges_2.34.1 S4Vectors_0.38.2
## [11] BiocGenerics_0.46.0 TFBSTools_1.38.0
## [13] JASPAR2020_0.99.10 SeuratObject_4.1.4
## [15] Seurat_4.4.0 Signac_1.11.0
##
## loaded via a namespace (and not attached):
## [1] RcppAnnoy_0.0.21 splines_4.3.1
## [3] later_1.3.1 BiocIO_1.10.0
## [5] bitops_1.0-7 tibble_3.2.1
## [7] R.oo_1.25.0 polyclip_1.10-6
## [9] XML_3.99-0.14 DirichletMultinomial_1.42.0
## [11] lifecycle_1.0.3 rprojroot_2.0.3
## [13] globals_0.16.2 lattice_0.21-8
## [15] MASS_7.3-60 magrittr_2.0.3
## [17] limma_3.56.2 plotly_4.10.2
## [19] sass_0.4.7 rmarkdown_2.25
## [21] jquerylib_0.1.4 yaml_2.3.7
## [23] httpuv_1.6.11 sctransform_0.4.0
## [25] spatstat.sparse_3.0-2 sp_2.1-0
## [27] reticulate_1.32.0 cowplot_1.1.1
## [29] pbapply_1.7-2 DBI_1.1.3
## [31] CNEr_1.35.0 RColorBrewer_1.1-3
## [33] abind_1.4-5 zlibbioc_1.46.0
## [35] Rtsne_0.16 purrr_1.0.2
## [37] R.utils_2.12.2 RCurl_1.98-1.12
## [39] pracma_2.4.2 GenomeInfoDbData_1.2.10
## [41] ggrepel_0.9.3 irlba_2.3.5.1
## [43] spatstat.utils_3.0-3 listenv_0.9.0
## [45] seqLogo_1.66.0 goftest_1.2-3
## [47] spatstat.random_3.1-6 annotate_1.78.0
## [49] fitdistrplus_1.1-11 parallelly_1.36.0
## [51] pkgdown_2.0.7 leiden_0.4.3
## [53] codetools_0.2-19 DelayedArray_0.26.7
## [55] RcppRoll_0.3.0 DT_0.30
## [57] tidyselect_1.2.0 ggseqlogo_0.1
## [59] farver_2.1.1 spatstat.explore_3.2-3
## [61] matrixStats_1.0.0 GenomicAlignments_1.36.0
## [63] jsonlite_1.8.7 ellipsis_0.3.2
## [65] progressr_0.14.0 motifmatchr_1.22.0
## [67] ggridges_0.5.4 survival_3.5-5
## [69] systemfonts_1.0.5 tools_4.3.1
## [71] ragg_1.2.6 TFMPvalue_0.0.9
## [73] ica_1.0-3 Rcpp_1.0.11
## [75] glue_1.6.2 gridExtra_2.3
## [77] xfun_0.40 MatrixGenerics_1.12.3
## [79] dplyr_1.1.3 withr_2.5.1
## [81] BiocManager_1.30.22 fastmap_1.1.1
## [83] fansi_1.0.5 caTools_1.18.2
## [85] digest_0.6.33 R6_2.5.1
## [87] mime_0.12 nabor_0.5.0
## [89] textshaping_0.3.7 colorspace_2.1-0
## [91] scattermore_1.2 GO.db_3.17.0
## [93] tensor_1.5 gtools_3.9.4
## [95] poweRlaw_0.70.6 spatstat.data_3.0-1
## [97] chromVAR_1.22.1 RSQLite_2.3.1
## [99] R.methodsS3_1.8.2 utf8_1.2.3
## [101] tidyr_1.3.0 generics_0.1.3
## [103] data.table_1.14.8 httr_1.4.7
## [105] htmlwidgets_1.6.2 S4Arrays_1.0.6
## [107] uwot_0.1.16 pkgconfig_2.0.3
## [109] gtable_0.3.4 blob_1.2.4
## [111] lmtest_0.9-40 htmltools_0.5.6.1
## [113] scales_1.2.1 Biobase_2.60.0
## [115] png_0.1-8 knitr_1.44
## [117] rstudioapi_0.15.0 tzdb_0.4.0
## [119] reshape2_1.4.4 rjson_0.2.21
## [121] nlme_3.1-162 zoo_1.8-12
## [123] cachem_1.0.8 stringr_1.5.0
## [125] KernSmooth_2.23-21 parallel_4.3.1
## [127] miniUI_0.1.1.1 AnnotationDbi_1.62.2
## [129] restfulr_0.0.15 desc_1.4.2
## [131] pillar_1.9.0 grid_4.3.1
## [133] vctrs_0.6.3 RANN_2.6.1
## [135] promises_1.2.1 xtable_1.8-4
## [137] cluster_2.1.4 evaluate_0.22
## [139] readr_2.1.4 cli_3.6.1
## [141] compiler_4.3.1 Rsamtools_2.16.0
## [143] rlang_1.1.1 crayon_1.5.2
## [145] future.apply_1.11.0 labeling_0.4.3
## [147] plyr_1.8.9 fs_1.6.3
## [149] stringi_1.7.12 deldir_1.0-9
## [151] viridisLite_0.4.2 BiocParallel_1.34.2
## [153] munsell_0.5.0 lazyeval_0.2.2
## [155] spatstat.geom_3.2-5 Matrix_1.6-1.1
## [157] hms_1.1.3 bit64_4.0.5
## [159] future_1.33.0 ggplot2_3.4.4
## [161] KEGGREST_1.40.1 shiny_1.7.5
## [163] SummarizedExperiment_1.30.2 ROCR_1.0-11
## [165] igraph_1.5.1 memoise_2.0.1
## [167] bslib_0.5.1 fastmatch_1.1-4
## [169] bit_4.0.5